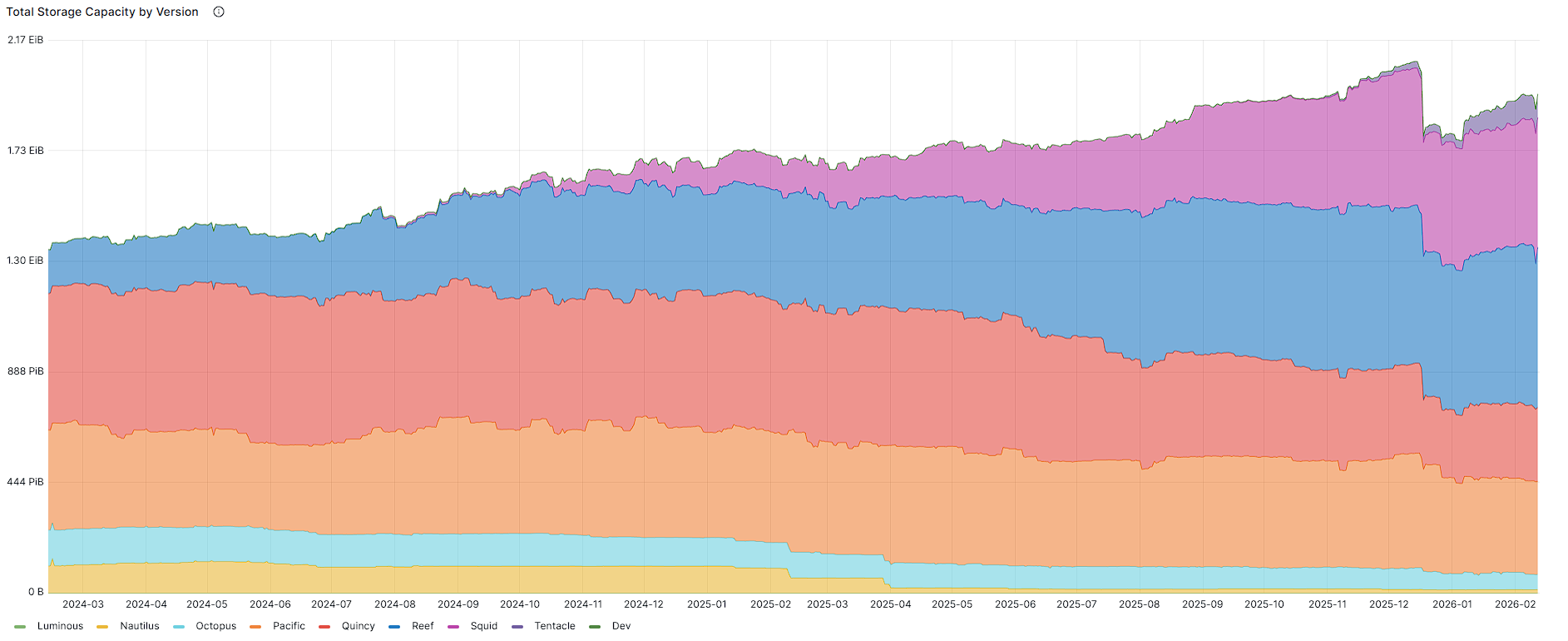
Total Storage Capacity by Version
Evidence-first consulting for Ceph clusters in production. I collaborate with your engineers to diagnose issues, reduce risk, and ship changes safely—no guessing.
I don’t sell “one-size-fits-all” configs or vague advice. If the right solution is “don’t change anything yet—collect evidence first”, that’s what I’ll recommend.
This keeps production safe and avoids expensive “tuning-by-superstition”.
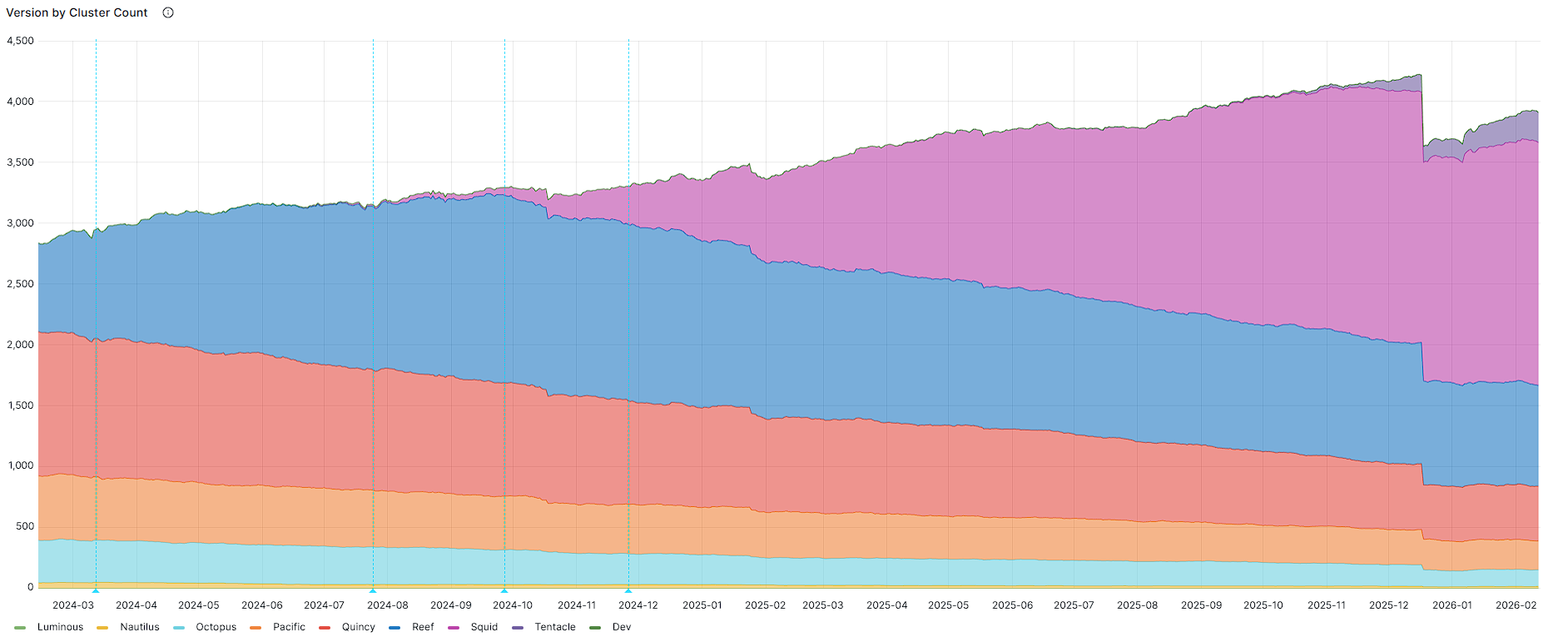
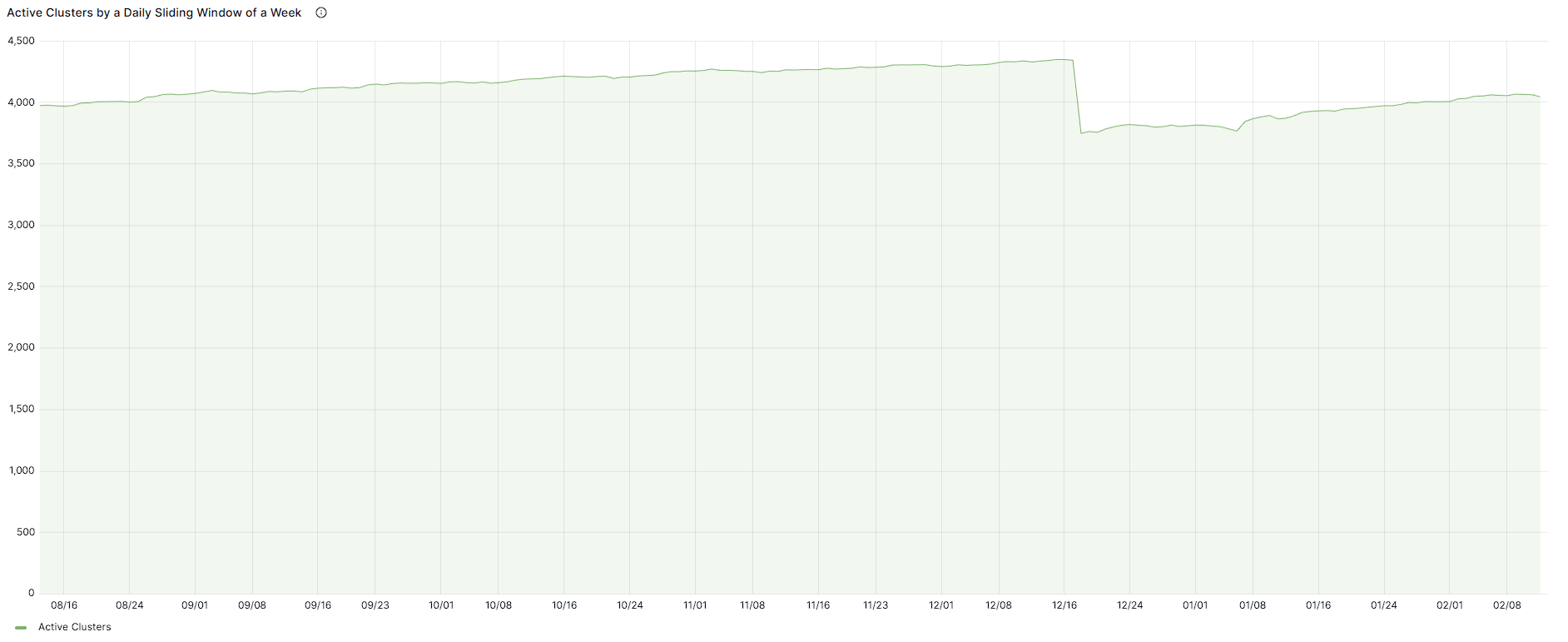
Snapshots from the public community dashboard.